Aria: First Open Multimodal Native MoE Model

Rhymes AI is proud to introduce Aria, the world’s first open-source, multimodal native Mixture-of-Experts (MoE) model.
In short, Aria features:
-
Multimodal native understanding:
- State-of-the-art performance on a wide range of multimodal and language tasks
- Pre-trained from scratch on a mixture of multimodal and language data
-
Lightweight and fast:
- Fine-grained mixture-of-expert model with 3.9B activated parameters per token
- Efficient and informative visual encoding of variable image sizes and aspect ratios
-
Long context window:
- Long multimodal context window of 64K tokens, captioning a 256-frame video in 10 seconds
-
Open:
- Open model weights 🤗, code repository 💻, technical report 📝 for collaborative development.
- License: Apache 2.0
Multimodal Native Performance
 Figure 1. Aria is a multimodal native model that excels at understanding text, vision, code.
Figure 1. Aria is a multimodal native model that excels at understanding text, vision, code.
Aria processes text, images, video, and code all at once, without needing separate setups for each type, demonstrating the advantages of a multimodal native model.
We provide a quantifiable definition for the term multimodal native:
A multimodal native model refers to a single model with strong understanding capabilities across multiple input modalities (e.g., text, code, image, video) that matches or exceeds the modality-specialized models of similar capacities.
We compared Aria against the best open and closed multimodal native models across established benchmarks, highlighting the following key observations:
- Best-in-Class Performance: Aria is the leading multimodal native model, demonstrating clear advantages over Pixtral-12B and Llama3.2-11B across a range of multimodal, language, and coding tasks.
- Competitive Against Proprietary Models: Aria performs competitively against proprietary models like GPT-4o and Gemini-1.5 on multimodal tasks, including document understanding, chart reading, scene text recognition, and video understanding.
- Parameter Efficiency: Aria is the most parameter-efficient open model. Thanks to the MoE framework, Aria activates only 3.9 billion parameters, compared to the full activation in models like Pixtral-12B and Llama3.2-11B.
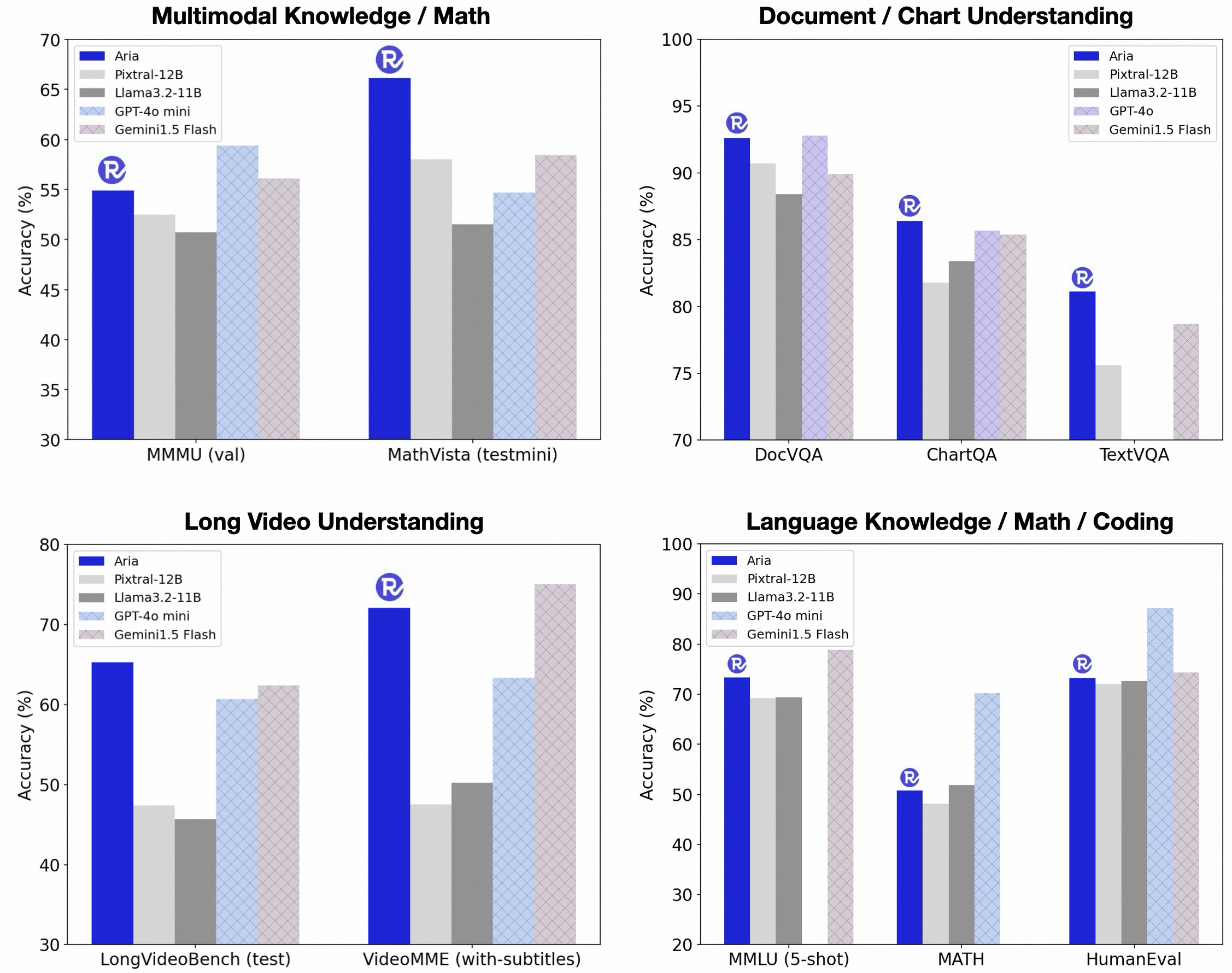 Figure 2. Aria shows best-in-class benchmark performance on multimodal, language, coding tasks.
Figure 2. Aria shows best-in-class benchmark performance on multimodal, language, coding tasks.
Long Multimodal Input Understanding
Multimodal data is often complex, involving long sequences that combine visuals and text, like videos with subtitles or long documents. For a model to be effective in real-world applications, it must be capable of understanding and processing such data efficiently.
Aria excels in this area, demonstrating superior long multimodal input understanding. It outperforms larger open models, proving its efficiency and effectiveness despite its size. When compared to proprietary models, Aria surpasses GPT-4o mini in long video understanding and outperforms Gemini-1.5-Flash in long document understanding. This makes Aria a preferred choice for processing extensive multimodal data in a compute-and-time-efficient manner, delivering faster and more accurate results in real-world scenarios.
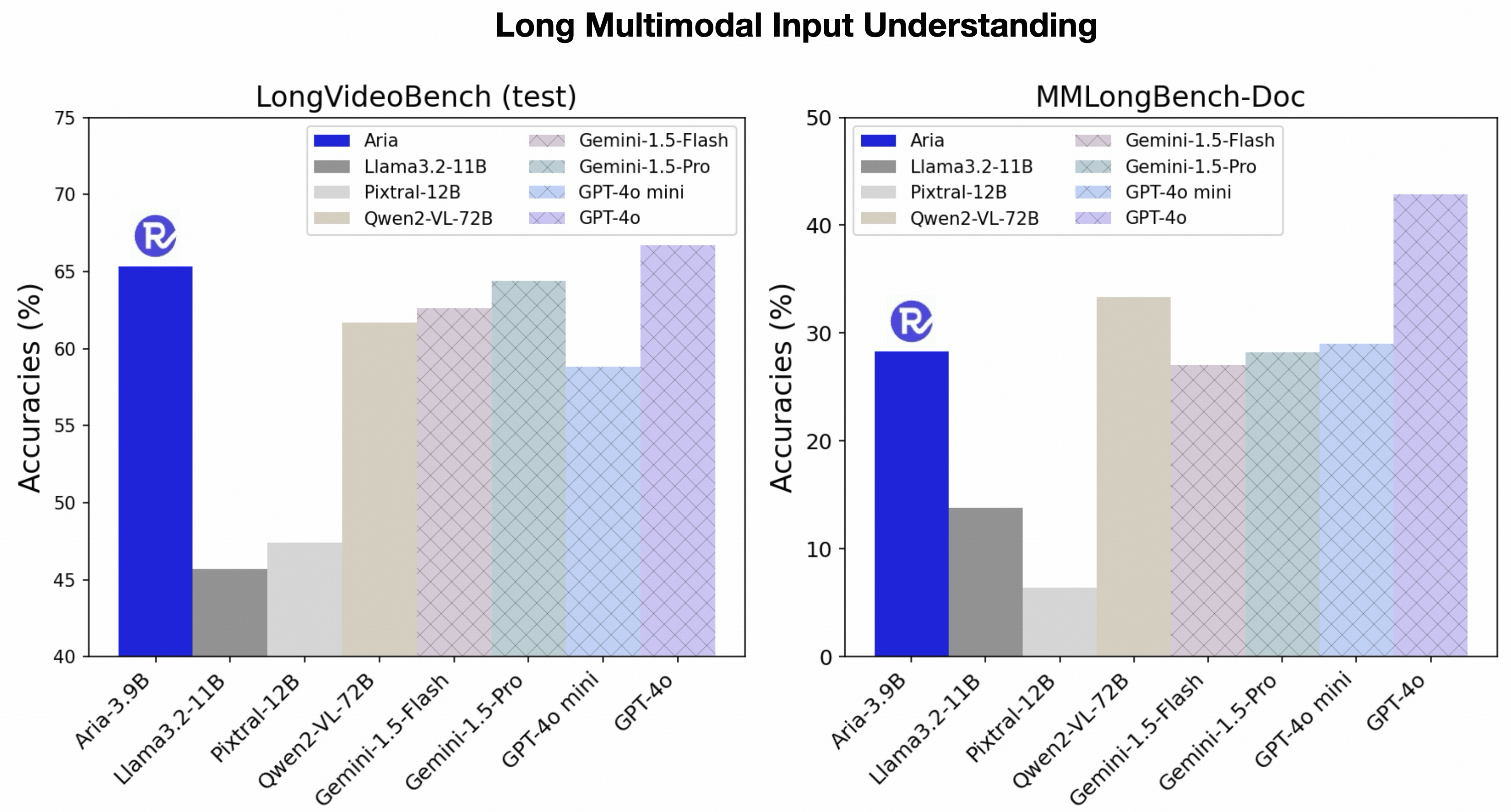
Figure 3. Aria excels in long multimodal input understanding, such as long video understanding.
Instruction Following
Aria is highly effective at understanding and following instructions on both multimodal and language inputs, performing better than top open-source models on both MIA-Bench and MT-Bench.
 Figure 4. Aria is highly effective at instruction following on multimodal and language inputs.
Figure 4. Aria is highly effective at instruction following on multimodal and language inputs.
Multimodal Native Training

Figure 5. Aria's 4-stage training pipeline for multimodal native understanding.
Aria is pre-trained from scratch using a 4-stage training pipeline, ensuring that the model progressively learns new capabilities while retaining previously acquired knowledge.
| 1. Language Pre-Training: | 2. Multimodal Pre-Training: | 3. Multimodal Long-Context Pre-Training: | 4. Multimodal Post-Training: |
|
|
|
|
Qualitative Examples
Multimodal Native Reasoning with Vision, Language, Coding Capabilities
Prompt:
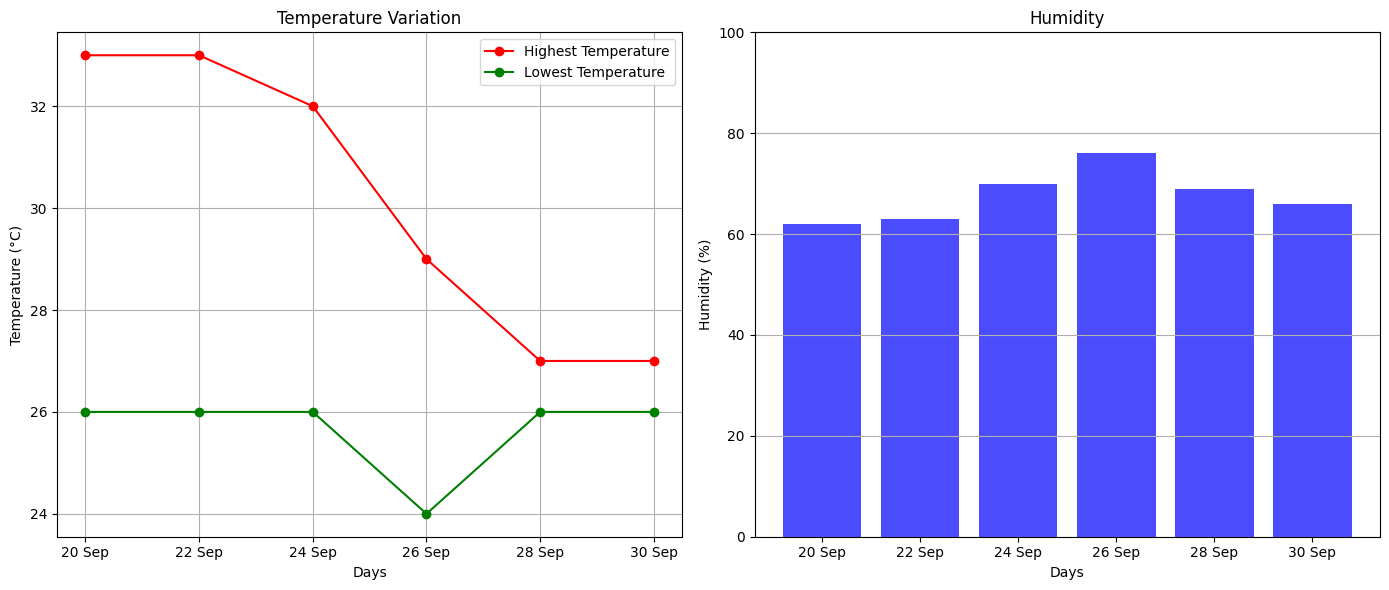
Organize the highest temperature, lowest temperature, and humidity for all even dates into a table.
Write a python code to draw a line chart for the temperatures, and a bar chart for the humidity. Use red and green colors for the temperatures, and use blue color for the humidity.
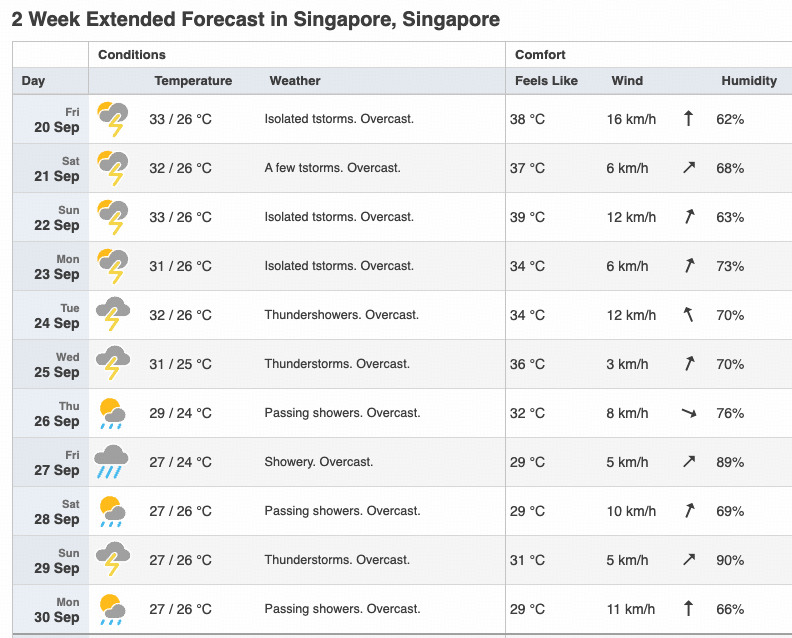 (source: https://www.timeanddate.com/weather/singapore/singapore/hourly)
(source: https://www.timeanddate.com/weather/singapore/singapore/hourly)
Aria response:
Sure! The table of temperature, humidity for even dates is as below:
| Date | Highest Temperature | Lowest Temperature | Humidity |
|---|---|---|---|
| 20 Sep | 33 °C | 26 °C | 62% |
| 22 Sep | 33 °C | 26 °C | 63% |
| 24 Sep | 32 °C | 26 °C | 70% |
| 26 Sep | 29 °C | 24 °C | 76% |
| 28 Sep | 27 °C | 26 °C | 69% |
| 30 Sep | 27 °C | 26 °C | 66% |
The Python code to draw the line chart for temperatures and the bar chart for humidity is as follows:
import matplotlib.pyplot as plt
# Data for even dates
days = ['20 Sep', '22 Sep', '24 Sep', '26 Sep', '28 Sep', '30 Sep']
high_temps = [33, 33, 32, 29, 27, 27]
low_temps = [26, 26, 26, 24, 26, 26]
humidity = [62, 63, 70, 76, 69, 66]
# Line chart for temperatures
plt.figure(figsize=(14, 6))
plt.subplot(1, 2, 1)
plt.plot(days, high_temps, 'r-', label='Highest Temperature', marker='o')
plt.plot(days, low_temps, 'g-', label='Lowest Temperature', marker='o')
plt.xlabel('Days')
plt.ylabel('Temperature (°C)')
plt.title('Temperature Variation')
plt.legend()
plt.grid(True)
# Bar chart for humidity
plt.subplot(1, 2, 2)
plt.bar(days, humidity, color='blue', alpha=0.7)
plt.xlabel('Days')
plt.ylabel('Humidity (%)')
plt.title('Humidity')
plt.ylim(0, 100)
plt.grid(axis='y')
plt.tight_layout()
plt.show()
Using the provided code snippet from Aria, we can generate the following visualizations:
Multimodal Native Reasoning - Financial Report Analysis
Prompt:
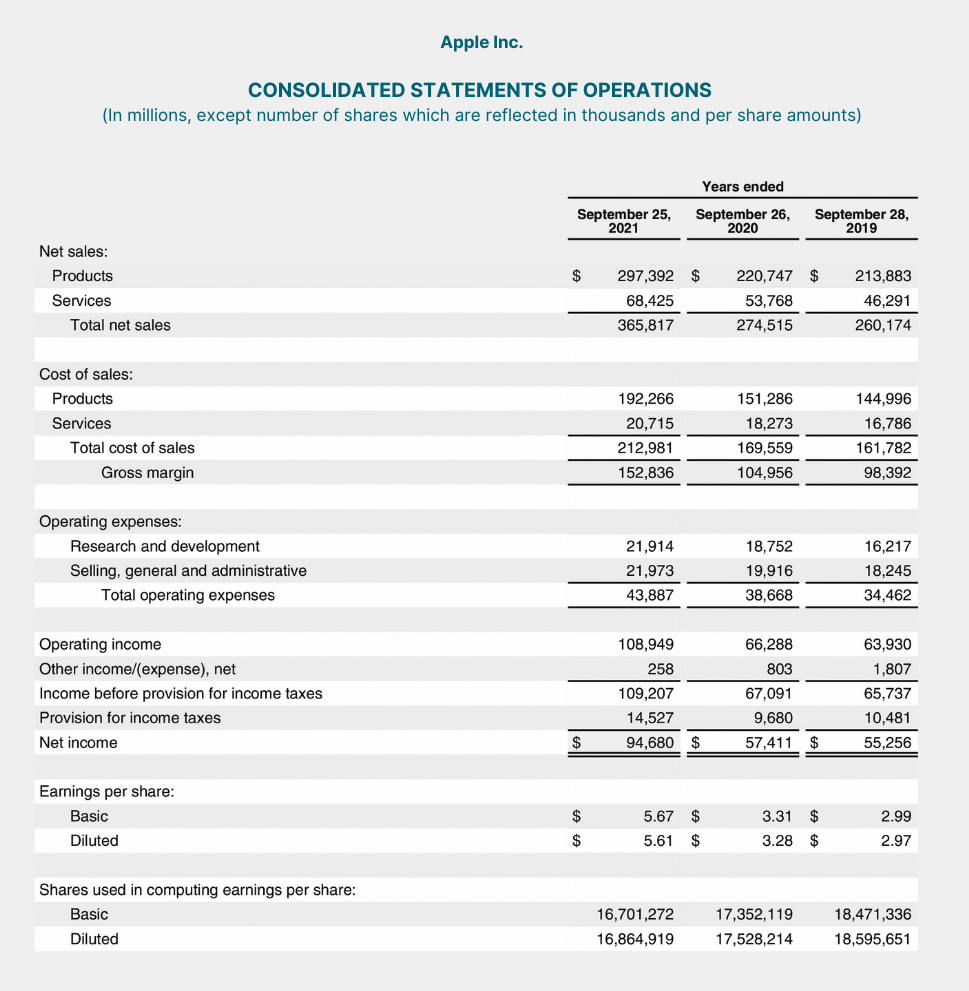
How does the company's profit margin change from year 2020 to 2021? What factors cause such changes? Answer step by step.
Aria response:
To determine how the company's profit margin changed from 2020 to 2021, we need to follow these steps:
-
Calculate the profit margins for both years:
- 2020:
- Net income: $57,411 million
- Total net sales: $274,515 million
- Profit margin = (Net income / Total net sales) * 100 = (274,515) * 100 ≈ 20.91%
- 2021:
- Net income: $94,680 million
- Total net sales: $365,817 million
- Profit margin = (Net income / Total net sales) * 100 = (365,817) * 100 ≈ 25.88%
- 2020:
-
Analyze the factors causing the change:
- Increase in Net Income: The net income increased from $57,411 million in 2020 to $94,680 million in 2021, showing a significant rise of $37,269 million.
- Sales Growth: Total net sales also increased from $274,515 million in 2020 to $365,817 million in 2021, indicating a strong growth in revenue.
- Cost Management: The cost of sales increased from $151,286 million in 2020 to $192,266 million in 2021, but the percentage increase in sales outpaced the increase in costs, leading to a higher profit margin.
- Operating Expenses: Operating expenses grew from $38,668 million in 2020 to $43,887 million in 2021, but the rise in sales was more substantial, positively impacting the profit margin.
Therefore, the company's profit margin improved from approximately 20.91% in 2020 to approximately 25.88% in 2021. This improvement is primarily due to a substantial increase in net income and effective cost management relative to the growth in total net sales.
Long Multimodal Context Window
Prompt:
Based on the five species in the images, draw a food chain. Explain the role of each species in the food chain.

Aria response:
- Mushrooms (Image 1): Decomposers, breaking down dead organic matter and recycling nutrients.
- Grass (Image 4): Primary producers, converting sunlight into energy via photosynthesis.
- Grasshopper (Image 2): Primary consumers, herbivores feeding on plants.
- Mouse (Image 3): Secondary consumers, herbivores that eat plants and possibly small insects.
- Hawk (Image 5): Tertiary consumers, predators that eat mice and other small animals.
Food Chain:
Grass → Grasshopper → Mouse → Hawk → Mushrooms
Explanation:
- Grass serves as the base, providing energy to grasshoppers.
- Grasshoppers eat the grass and are then consumed by mice.
- Mice are preyed upon by hawks.
- Hawks are apex predators, feeding on mice.
- Mushrooms decompose dead matter, recycling nutrients back into the ecosystem.
Long Multimodal Input - Paper Reading
Prompt:
Summarize the key contribution of the paper, and explain how it uses various figures and tables to showcase such contribution.
Aria response:
The paper introduces LONGVIDEOBENCH, a benchmark for evaluating Large Multimodal Models (LMMs) in long-context video-language understanding. It addresses the challenge of processing longer video inputs by proposing a question-answering benchmark that tests the models' ability to understand and reason about video contexts interleaved with up to an hour-long video. This benchmark includes 3,763 videos with diverse themes and 6,678 human-annotated multiple-choice questions across 17 categories.
The key contribution is the comprehensive evaluation of LMMs' performance on long-form video understanding, highlighting the limitations of existing models in handling extended inputs. The paper demonstrates that while proprietary models like GPT-4 and Gemini-1.5-Pro show improvements with longer inputs, open-source models lag significantly behind.
Figures and tables are used to illustrate these points:
- Figure 1: Demonstrates the performance of different models on the benchmark, showing how accuracy varies with the number of frames.
- Figure 2: Provides examples of the 17 categories of referring reasoning questions.
- Table 1: Lists the benchmark and previous benchmarks for comparison.
- Table 2: Details the 17 categories of referring reasoning questions.
- Table 3: Shows statistics of videos in LONGVIDEOBENCH by category groups and duration.
- Table 5: Validation set results categorized by duration groups.
- Table 7: Test set leaderboard of LMMs by duration groups and question categories.
These visual aids help in understanding the performance metrics, the diversity of the dataset, and the specific challenges posed by longer videos and complex questions, thus emphasizing the need for improved models in long-form video understanding.
Long Multimodal Input - Split Video and Write Scene Descriptions
Prompt:
Please split this video into scenes, providing start time, end time, a title and detailed descriptions for each scene.
(source: https://www.youtube.com/watch?v=Gh22bt1GYoQ)
Aria's Response:
Certainly! Here are the scenes from the video, including their start and end times, titles, and detailed descriptions:
| Scene 1: Introduction | Scene 2: Cooking Demonstration | Scene 3: Potato Preparation | Scene 4: Potato Mashing | Scene 5: Potato Transfer | Scene 6: Therapist Matching Quiz | Scene 7: Cooking Continuation | Scene 8: Potato Wrapping | Scene 9: Cooking Meat | Scene 10: Final Preparation | Scene 11: Plating the Dish | Scene 12: Conclusion |
|
|
|
|
|
|
|
|
|
|
|
|
The video has a total of 12 scenes, each with a specific focus and detailed description.
Model Architecture
Aria comprises a vision encoder and a mixture-of-experts decoder. The vision encoder produces visual tokens for images/videos in their native aspect ratio. It operates in three resolution modes: medium, high, and ultra-high. A medium-resolution image is represented using 128 visual tokens; a high-resolution image is represented using 256 visual tokens; an ultra-high resolution image is dynamically decomposed into multiple high-resolution sub-images.
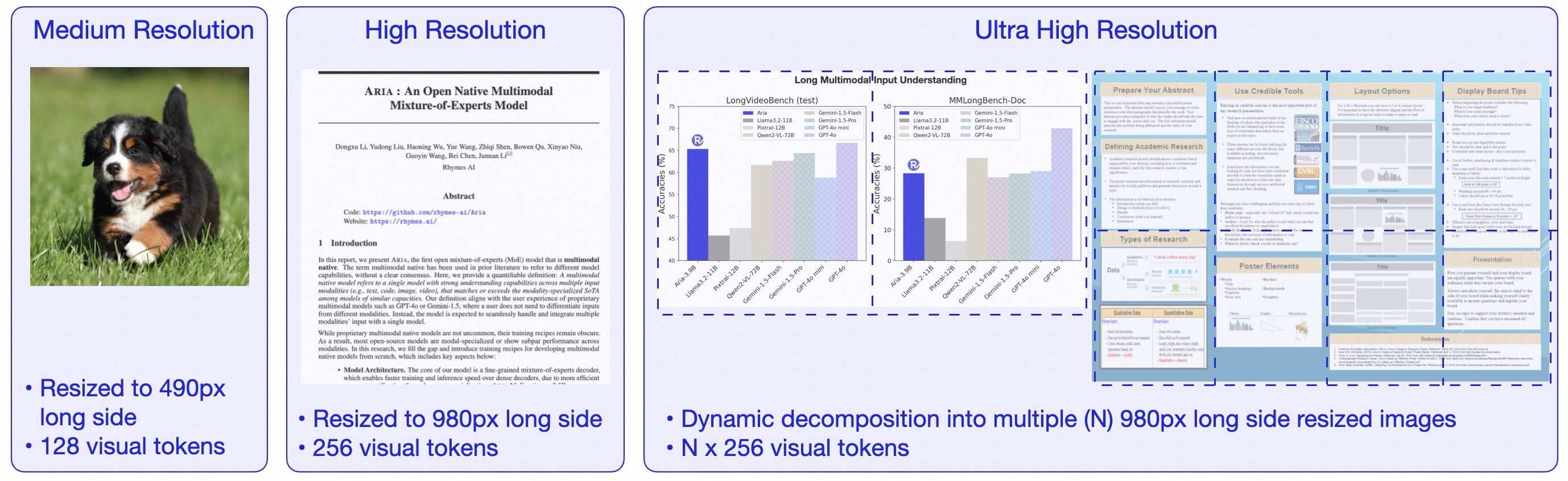 Figure 6. Aria's vision encoder operating in three resolution modes: medium, high, and ultra-high, with varying token representations.
Figure 6. Aria's vision encoder operating in three resolution modes: medium, high, and ultra-high, with varying token representations.
The MoE decoder is multimodal native, and makes predictions conditioned on both language and visual input tokens. Specifically, Aria has 66 experts in each MoE layer, 2 of the 66 experts are shared among all inputs to capture common knowledge, whereas 6 more experts are activated for each token by a router module.

Figure 7. Aria's multimodal native MoE decoder.
Developing with Aria
Aria is designed to be developer-friendly, offering extensive support and flexibility. To facilitate development and collaboration, Rhymes AI provides a codebase that facilitates adoptions of Aria in downstream applications.
The codebase features:
- Fast and easy inference with Transformers or vllm
- Cookbooks and best practices for using Aria
- Fine-tuning Aria on various dataset formats, using as few as a single GPU
Looking Ahead
With the launch of Aria, we're aiming to redefine how AI integrates into our lives. Our focus is on creating tools that genuinely benefit people, expanding what’s possible in both technology and human connection.
We are excited to collaborate with researchers, developers, and innovative organizations to explore new frontiers in AI. Together, we can build solutions that are not only cutting-edge but also impactful and meaningful for society.
We believe the future of AI is multimodal, efficient, and seamlessly integrated into everyday experiences. Aria is just the beginning. Let’s shape the future of AI together.