Allegro: Advanced Video Generation Model

We're excited to announce the open-source release of Allegro, Rhymes AI's advanced text-to-video model. Allegro is a powerful AI tool that transforms simple text prompts into high-quality, short video clips, opening up new possibilities for creators, developers, and researchers in the field of AI-generated video. We hope Allegro will be able to enable visual creativity, imagination, and collaboration in the community.
Allegro at a Glance
Allegro empowers users to generate high-quality, 6-second videos at 15 frames per second and 720p resolution from simple text prompts. This quality level allows for the efficient creation of various cinematic themes from detailed close-ups of people, animals in action across various settings, to nearly any scene you can imagine based on text descriptions. The model's versatility offers users the flexibility to explore diverse creative ideas within the constraints of the 6-second format.
Key Features:
-
Open Source: Full model weights and code available to the community, Apache 2.0!
-
Versatile Content Creation: Capable of generating a wide range of content, from close-ups of humans and animals to diverse dynamic scenes.
-
High-Quality Output: Generate detailed 6-second videos at 15 FPS with 720x1280 resolution, can be interpolated to 30 FPS with EMA-VFI.
-
Small and Efficient: Features a 175M parameter VAE and a 2.8B parameter DiT model. Supports multiple precisions (FP32, BF16, FP16) and uses 9.3 GB of GPU memory in BF16 mode with CPU offloading. Context length is 79.2k, equivalent to 88 frames.
In this blog post, we'll dive deep into the core technologies that power Allegro, exploring its three key components:
- Large-scale video data processing
- Compression of raw video into visual tokens
- Scale-up video diffusion Transformer
We'll also showcase some impressive demos and discuss ongoing feature developments that promise to push the boundaries of AI-generated video even further.
The Technology Behind Allegro
The model's capabilities are built on core technologies that process video data, compress raw video, and generate video frames, enabling the transformation of text prompts into short video clips.
1. Large-Scale Video Data Processing
To create a model capable of generating diverse and realistic videos, this required a system to process an enormous amount of video data. With that in mind, we designed systematic data processing and filtering pipelines to derive training videos from raw data. The process is sequential and includes the following stages:
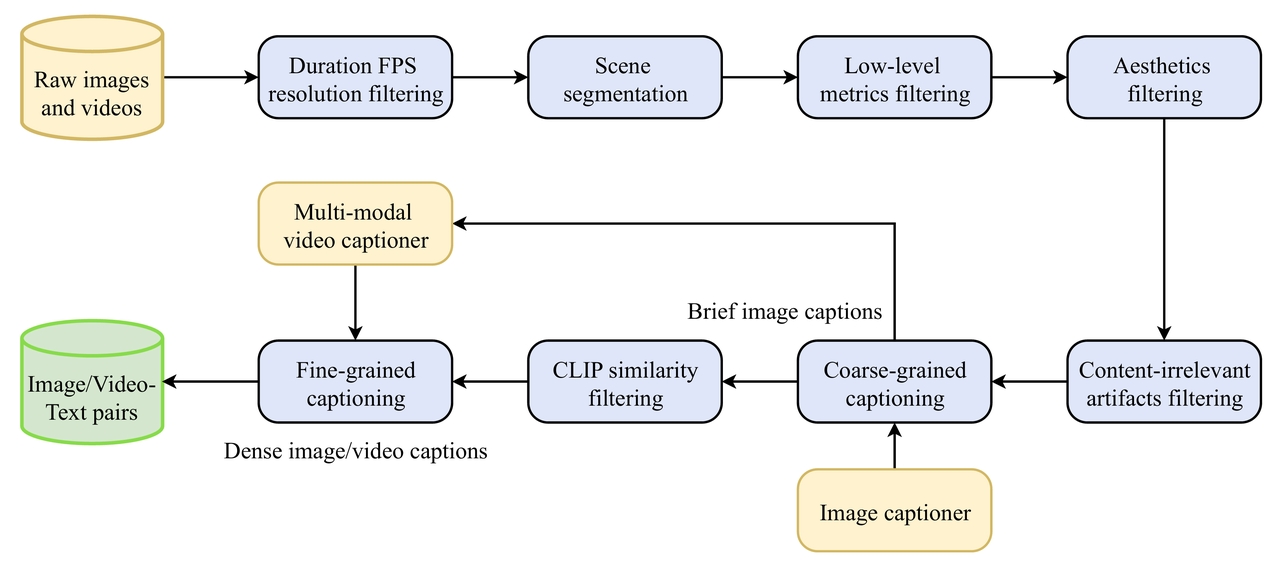
Next, based on the metrics obtained during the processing, we developed a structured data system that allows for multi-dimensional classification and clustering of the data, facilitating model training and fine-tuning for various stages and purposes. We share our detailed recipe in our tech report.
2. Compressing Video into Visual Tokens
One of the key challenges in video generation is managing the sheer amount of data involved. To address this, we compress raw videos into smaller visual tokens while preserving essential details, enabling smoother and more efficient video generation. Specifically, we designed a Video Variational Autoencoder (VideoVAE), which encodes raw videos into a spatio-temporal latent space. The VideoVAE is built on a pre-trained image VAE, extended with spatiotemporal modeling layers to harness the spatial compression capabilities effectively.
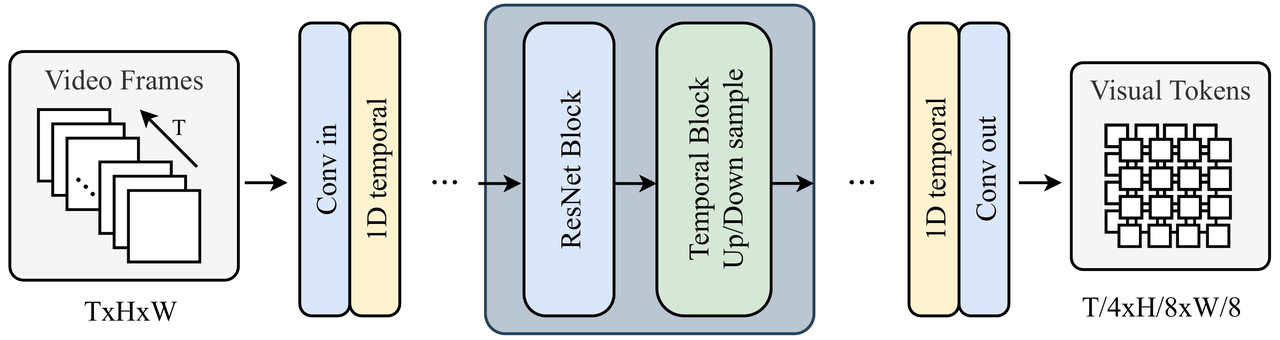
3. Scaling Video Diffusion Transformer
The core of Allegro's video generation capabilities lies in its scale-up Diffusion Transformer architecture, which applies diffusion models to generate high-resolution video frames, ensuring quality and fluidity in video motion.
The backbone network of Allegro is built upon the DiT (Diffusion Transformer) architecture with 3D RoPE position embedding and 3D full attention. This architecture efficiently captures spatial and temporal relationships in video data.
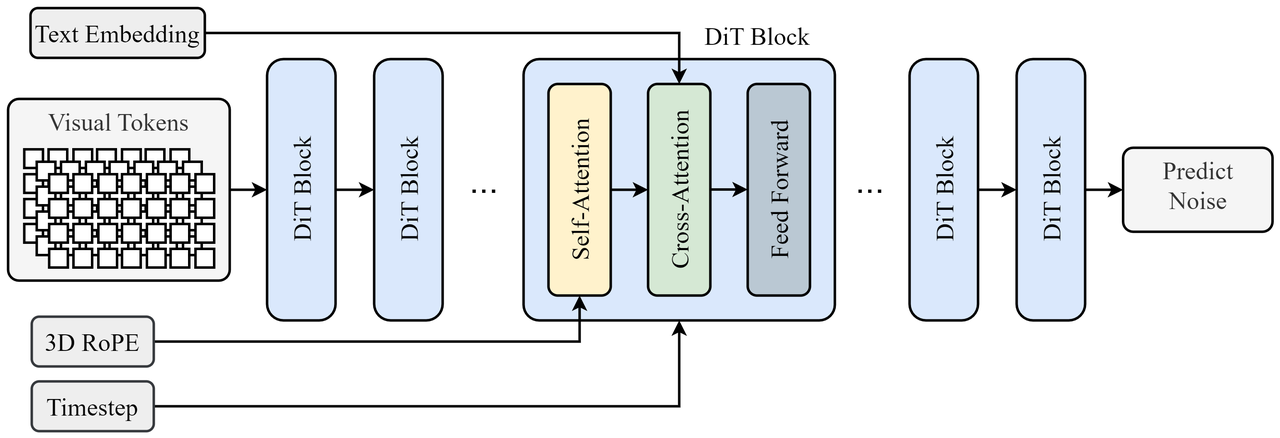
Compared to traditional diffusion models that utilize UNet architectures, the Transformer structure is more conducive to model scaling. By leveraging 3D attention, DiT processes both the spatial dimensions of video frames and their temporal evolution, allowing for a more nuanced understanding of motion and context.
The combination of 3D attention mechanisms and the scale-up capabilities of the DiT model significantly enhances performance, allowing for the generation of high-quality videos with rich detail and fluid movement.
Allegro in Action
When put to work, Allegro transforms diverse text descriptions into short video clips. Given the prompt "Pink fish swim in the sea" it generates a video that captures the fluid motion of the colorful fish gliding through water. In contrast, with "An astronaut riding a horse," Allegro creates a more fantastical scene, showing a figure in a spacesuit atop a horse, set against a dusty background. These examples demonstrate Allegro's range in visualizing both natural and imaginative scenarios, from underwater scenes to surreal concepts. For more examples, visit our Allegro gallery.
Future Developments
We're excited about the current capabilities of Allegro, but this is just the beginning. Our team is actively developing more advanced features for Allegro, including image-to-video generation, motion control, and support for longer, narrative-based, storyboard-style video generation.
Get Involved with Allegro
Our goal is to make AI-driven video creation more accessible to a wider range of users. By making Allegro open source, with both model weights and code available, we're inviting the community to explore, unleash their creativity, and build upon our work with the hope for collaborative advancement in AI-generated video technology. Here's how you can get started:
- Read our Technical Report for in-depth details
- Access Allegro weights on Hugging Face
- Explore Allegro inference code on GitHub
- Or try directly on our Discord (available soon): by filling in this wait list
For any inquiries or discussions, feel free to join our Discord community or contact us through our feedback form.
We can't wait to see what you'll create with Allegro!
Rhymes Team